A leading global financial services firm that provides wealth management, asset servicing, asset management, and banking solutions to corporations, institutions, and affluent individuals, founded over 100 years ago. This stalwart institution, bloated with legacy processes and technologies, focuses strongly on a highly tailored client centric approach. This means that enabling scalable data-driven solutions is of the utmost importance as they gear up for the future.
Problem Overview
A deep understanding of the customer is a powerful tool when it comes to cross selling and extracting additional value from an established relationship. Hence, an example of a data product our client was looking to deliver as part of this new data platform was a solution that modeled characteristics of existing customers - using a wide cross section of existing data - to identify a population of ‘similar’ customers. Starting with an ‘ideal’ customer, ideal because they might generate a significant revenue stream, and using this to determine a population of ‘similar’ customers the client planned to cross sell additional products and services to this newly identified group. This particular product was an experimental ML model that they hoped would yield a return.
Thinking more broadly about the scalable delivery of this type of data product and future - yet undetermined ideas - our client had several specific functional requirements that a data platform would need to meet in order to enable this type of experimentation and potential value delivery across the organization.
Centralize data from various sources, while keeping the data engineering effort as low as possible
Standardize data in a unified Data Lake layer, while facilitating exploratory/sandbox access
Enable various teams, including data scientists & BI dashboard authors, access to prepare and model data to fit their specific needs for Data Product Delivery, without impacting each other’s’ development lifecycles
Background:
High quality data is the first step in enabling data product delivery. Whether it be a customer segmentation analysis, performed by the marketing department to drive a more targeted campaign for a new product launch, or a cash flow modeling exercise performed by the FP&A group to manage liquidity while optimizing business performance; all depend on high-quality, accessible, and understood data.
The typical steps taken to source organizational data for development of any data product or analysis are as follows:
Identifying sources & owners
Building integrations
Operationalizing the integrations
Analyzing and preparing the data for the intended use
By this point it often becomes necessary to refine existing integrations or even source additional data
This all leads to added rework and time spent waiting to actually derive real value from the analysis
Finally, the company is ready to deploy the analysis or insight – in our example the customer segmentation analysis, or cash flow model.
Only once the data product is deployed can it produce organizational value (in the form of increased revenue or reduced costs) and hence a positive return on investment, which overcomes the initial investment required to bring the product to life. Activities until this point will not yield significant value by themselves. New integrations or data engineering work won't produce value unless used appropriately and centralized data is of little value unless someone does something useful with it.
The data lifecycle is rarely linear; integration refinement and data sourcing efforts are ongoing and iterative, hence a solution or approach with the characteristics listed below is needed:
Streamlines and reduces the time and effort spent on activities that do not provide a positive ROI by themselves (see above visual)
Thus, allowing finite resources to be deployed towards positive ROI activities, such as refining existing products or insights, and developing and deploying new ones. An example of this is expensive data scientists spending more time experimenting vs. building pipelines to get more data.
Approach & Technologies Leveraged:
Our approach to data management and product delivery centers on several guiding principles as follows:
Metadata Driven Ingestion
Utilizing Data Contracts minimizes the need for complex and resource-intensive reactive data governance efforts as core data attributes are captured within these contracts
Prioritized Data Governance, via the use of data contracts, ensures there is a clear understanding of all the data that is ingested and delivered across the data platform
Reusable Data Engineering Patterns
Reusable data pipelines and ingestion processes for efficient scalability across similar data sources which leverage data contracts
Reduce platform complexity and key-person risk by adhering to a consistent development standard
Incorporate best-in-class DevOps practices for streamlined development and delivery
Data Product Alignment
Centralize key data assets in cost-effective cloud storage and conform using serverless compute resources
Enable innovation and experimentation without the need to move centrally stored data, allowing for data distribution across multiple teams while maintaining a single copy of the data
Leverage Best-In-Class Cloud Tooling & Practices
Empower data resources to focus on enabling data use-cases, not managing infrastructure
Optimize data platform maintenance and scalability with cost-effective PaaS cloud data technologies
Optimize data platform development and deployment with best-in-class cloud DevOps practices
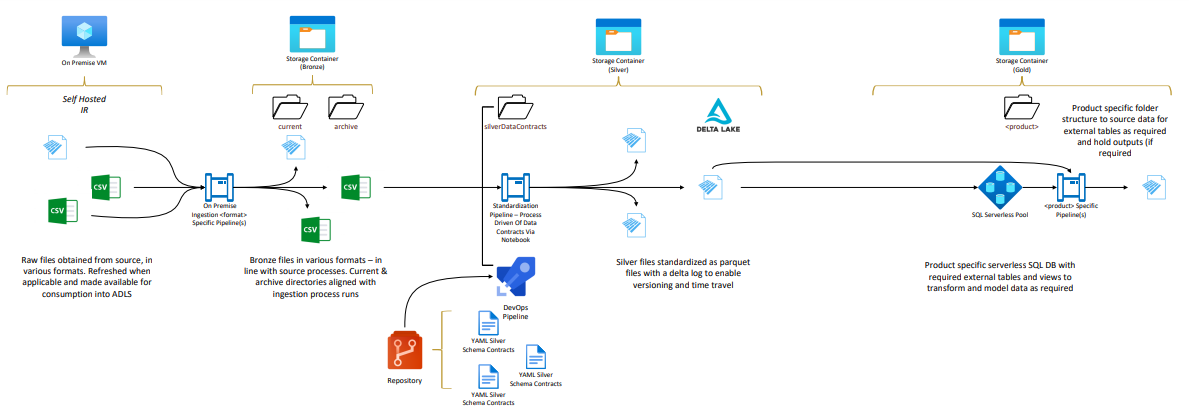
In our client’s use case, the solution utilized a Delta Lakehouse platform built on Azure Synapse, leveraging a medallion Data Lake Architecture – Bronze, Silver and Gold Layers – along with metadata driven ingestion and standardization processes driven via repository housed data contracts. Specific technology and approaches are listed below.
Data Contract Driven Development
A data contract is a document between a data producer(s) and data consumer(s). The primary purpose of a data contract is to ensure dependable, high-quality data that garners trust from all stakeholders. Data contracts are a technology agnostic solution that:
Offer insights into dependencies and coupling among data domains, along with consistent and traceable documentation for long-term strategic development
Are critical components of metadata-driven integration frameworks, which are crucial to streamlined data ingestion and delivery
Proactively capture critical components of data governance and data management frameworks
Integrate seamlessly with the leading Modern Data Platforms
Azure Synapse Modern Data Platform
Kenway Consulting recommended the use of Azure Synapse Analytics as the central data processing platform. This choice was driven by the platform's integrated capabilities, which combine big data and data warehousing, allowing for seamless ingestion, preparation, and serving of data. The platform's architecture supports both on-demand and provisioned resources, offering flexibility in efficiently managing diverse workloads.
Serverless SQL for Data Modeling
With the standardized (silver) data residing in Azure Blob Storage, Kenway implemented serverless SQL models within Azure Synapse. This serverless approach allowed for on-the-fly querying and modeling without the need for dedicated compute infrastructure. The serverless SQL capabilities seamlessly integrated with the existing Azure Synapse environment, providing a cost-effective solution for modeling, and preparing data for analysis.
The Solution:
Keeping the above goal of streamlining low value activities to allow for more time spent developing ROI-generating products, our solution incorporated the following feature sets:
Metadata-driven ingestion via data contracts was developed per source architype – flat file sources, database sources, and application events. This minimized the effort needed to onboard new data sources and reduced data engineering complexity as additional source objects could be added via configuration. A Silver Delta File layer, exposed via external tables in a Serverless SQL workbench, allowed easy exploration of the data via familiar tools such as SQL Server Management Studio and Power BI.
Gold Product, use case-specific, Serverless databases driven off the same underlying Silver Delta files, allowed different teams to model and conform data as required for their use cases, while governance was established over the underlying shared silver assets using GIT managed data contracts; exposing familiar change control patterns as would be employed in any SDLC, such as branching, version history, code review and merge approval processes.
Key to this solution and approach was a data contact-driven development approach which specifically enabled the following:
PROACTIVE GOVERNANCE: Data contracts require users to maintain up-to-date documentation to facilitate changes for both new and existing datasets
SCALABLE INGESTION FRAMEWORK FOR RAPID DATA HYDRATION: Data contracts support a metadata-driven ingestion framework, minimizing the effort required for ingesting new objects to mere configuration adjustments rather than starting from scratch
SEAMLESS INTEGRATION WITH LEADING MODERN DATA PLATFORMS: Data Contracts seamlessly integrate with leading PaaS data platforms, like Azure Synapse and Databricks, and general DevOps best practices streamlining the Analytics Development Lifecycle
FOCUS ON HIGH ROI INITIATIVES: By optimizing data contracts, resources can shift their focus towards high-value data initiatives, effectively streamlining low-priority tasks
CONSISTENT, STANDARDIZED, AND UNDERSTOOD DATA: By aligning the creation mechanics of data assets with their definitions in data contracts, quality issues are preemptively addressed before they materialize.
Conclusion
Kenway created a unified data platform that supports rapid and efficient data product delivery, aligning perfectly with the client's needs.
Centralized Data with Minimal Engineering Effort: Through our metadata-driven ingestion process and data contracts, Kenway centralized data from multiple sources while minimizing the data engineering efforts. This approach streamlined the integration of new data sources, reducing complexity and time to value.
Standardized Data for Exploratory Access: Our unified data layer, supported by Silver Delta Files and Serverless SQL workbenches, enabled consistent and exploratory access to data. This standardization allowed various teams to interact with the data using familiar tools, ensuring consistent data usage while supporting diverse analytical needs.
Enabling Team-Specific Data Preparation and Modeling: By utilizing Gold Product-specific Serverless Databases and maintaining governance through GIT-managed data contracts, Kenway empowered different teams to prepare and model data independently. This ensured efficient collaboration and innovation without disrupting each other's development lifecycles.
Streamlined Low-Value Activities: Our solution reduced the time spent on low-value activities through a metadata-driven ingestion framework and proactive governance mechanisms. This allowed the client's resources to focus on high-value, ROI-generating initiatives, such as refining existing products and developing new insights.
How Kenway Consulting Can Help
At Kenway Consulting, our Modern Data Enablement services are designed to help organizations capitalize on data as a strategic asset. We leverage cloud technology and a composable data ecosystem to optimize data utilization and analytics. Our approach focuses on integrating data and analytics into your business strategy, driving data quality, automating data consolidation, and delivering actionable insights to key stakeholders.
Why Choose Kenway?
Vendor-Agnostic Approach: We select and implement the best technology solutions tailored to your needs, ensuring you get the most effective tools for your specific requirements.
Expert Guidance: Our team provides strategic and technical expertise across all stages of the data lifecycle, helping you navigate complex data challenges and achieve your goals.
Proven Success: We have a track record of helping clients transform their data management practices, resulting in improved decision-making and innovation.
In summary, by partnering with Kenway Consulting, our client benefited from a comprehensive and scalable data solution that streamlined their data processes, enhanced data quality, and enabled rapid deployment of data products. This case study underscores our commitment to delivering tailored, high-impact solutions that drive business value and support strategic objectives in the financial services industry. If you’re interested in discovering how Kenway Consulting can help your organization leverage scalable data solutions and enhance your financial services data management, please reach out to us.
Kenway collaborated with a large financial services organization serving high-net-worth clients worldwide. The client faced inefficiencies in data product delivery...
Have a problem that needs solving? A process that could be smoother? Reach out to Kenway Consulting for a customized solution that fits your needs today.